开云kaiyun官方网站从而灵验擢升模子性能-外围足球软件app下载


新智元报说念
裁剪:LRST
【新智元导读】华中科技大学的接头东说念主员提议了MoE Jetpack框架,通Checkpoint Recycling体式和SpheroMoE结构,将密集激活模子的预查考权重微调为搀和内行(MoE)模子,从而免去了MoE模子的预查考经过,大幅擢升了MoE鄙人游任务中的精度和拘谨速率。
搀和内行模子(MoE, Mixture of Experts)是一种通过动态激活收罗的部分结构来擢升贪图遵守的架构,不错在保捏相对踏实的贪图资本的前提下大幅增多参数目,从而灵验擢升模子性能。
这一特色使得MoE简略兼顾模子的限制与遵守,已闲居应用于千般大限制任务。
然则,MoE模子时常需要在大型数据集上预查考以取得理思性能,导致其对时辰和贪图资源的需求极高,这也驱散了其在深度学习社区中的普及性。
为处置这一问题,华中科技大学的接头东说念主员提议了MoE Jetpack框架,哄骗密集模子的预查考权重(Dense checkpoints)来微调出视觉搀和内行模子(MoE,Mixture of Experts)。
当今,这项使命已被NeurIPS 2024接纳。

论文标题:MoE Jetpack: From Dense Checkpoints to Adaptive Mixture of Experts for Vision Tasks
论文地址: https://arxiv.org/abs/2406.04801
代码地址: https://github.com/Adlith/MoE-Jetpack
MoE Jetpack框架的中枢改进包括:
1. Checkpoint recycling:通过采样密集模子权重产生各异化的内行,构成MoE模子的启动化权重,从而加快模子拘谨、擢升性能,并幸免大限制的MoE模子预查考。
2. SpheroMoE Layer:通过养息MoE结构,哄骗交叉防备力机制进行内行分拨,将query和key投影到超球空间以擢升微调经过的踏实性,并通过一系列内行正则化体式灵验缓解MoE模子微调经过中的过拟合局势。
实践驱散标明,MoE Jetpack在多个数据集和收罗结构上杀青了显赫的性能擢升。在ImageNet-1K上,模子拘谨速率擢升2倍,准确率提高了2.8%;在小限制数据集上,拘谨速率可达8倍擢升,准确率擢升卓绝30%。
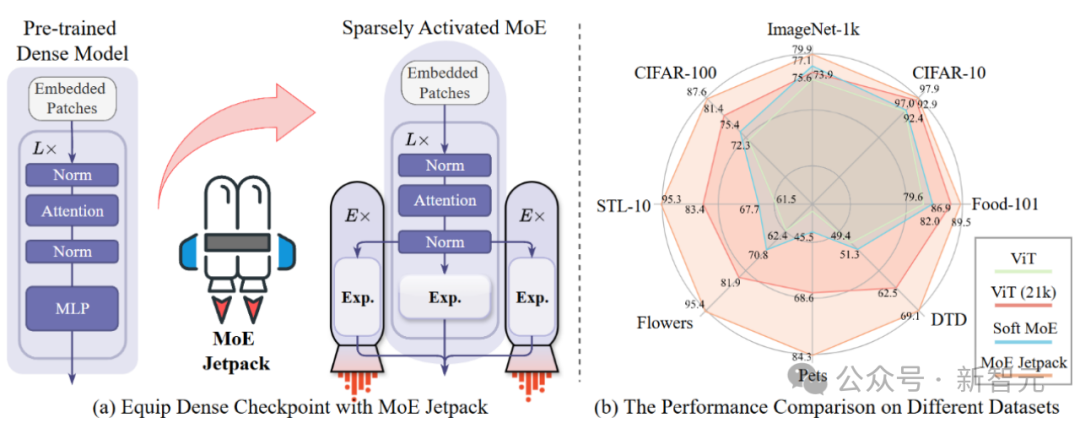
图1 (a)MoE Jetpack将密集预查考权重升沉为MoE模子的启动化权重,在性能擢升的同期保捏等效的FLOPs。(b) 未预查考的ViT、微调的ViT、未预查考的Soft MoE 与MoE Jetpack在多个视觉数据集上的性能比拟。
在多个下流数据集上的实践标明,该框架简略高效哄骗预查考权重,杀青更快的拘谨速率和更优的性能发扬。
接头体式
MoE Jetpack的中枢由两个阶段构成:Checkpoint Recycling(用于MoE模子的启动化)和SpheroMoE层(用于微调MoE模子),如下图所示。
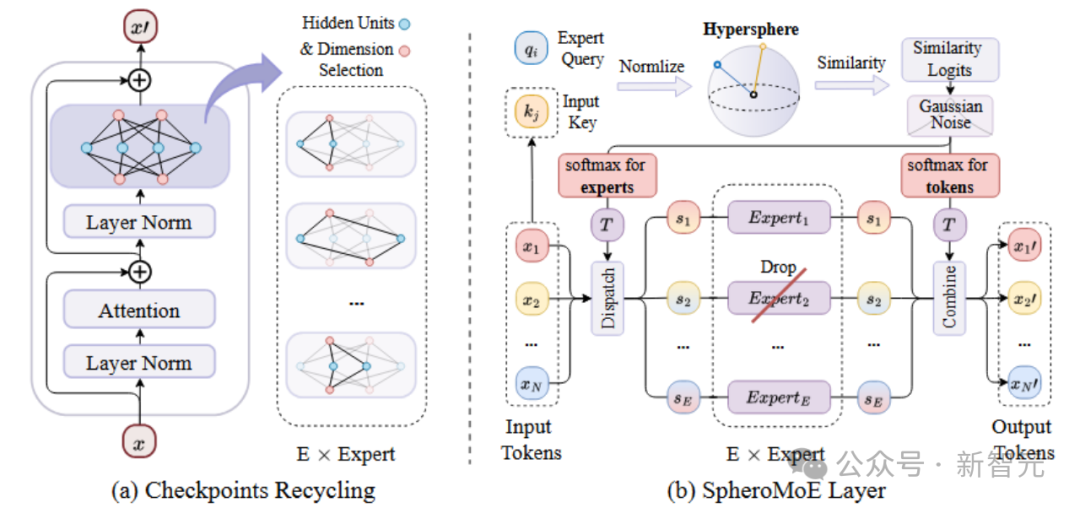
图2 Checkpoint Recycling和SpheroMoE结构
Checkpoint Recycling:看成MoE Jetpack的基础阶段,Checkpoint Recycling通过将预查考的密集模子权重转折为高质地的MoE启动化权重,使新模子在性能和拘谨速率上都得以擢升。
具体地,Checkpoint Recycling从密集权重的多层感知器(MLP)中采样出部均权重构建内行层,以确保内行的千般性和纯真性。
本文比拟了四种主要的权重回收计策:
1. 首要性采样(Importance-Based Weight Sampling):首要性采样是 MoE Jetpack 默许的权重采样体式,通过贪图输出特征的均值,选定top-d' 个最首要的特征维度,同期左证荫藏单位的激活值大小进行零丁采样。这种体式确保每个内行包含要道的特征和荫藏单位,有助于擢升模子的启动化质地和查考遵守。
2. 图辩别法(Co-Activation Graph Partitioning):图辩别法通过构建共激活图,将常一皆激活的荫藏单位分组,使用图辩别算法(如 Metis),将密集权重的荫藏单位辩别红多个子图,组合不同的子图造成不同内行层,确保内行专注于不同的功能区域,擢升模子的特征抒发才略。
3. 均匀采样(Uniform Weight Selection):均匀采样在特征维度和荫藏单位上均匀选定权重,保证每个 MoE 内行层平衡散播启动化权重。此体式杀青浅显,但不探讨特征首要性,因此性能擢升后果较为一般。
4. 随即采样(Random Weight Sampling):随即采样在特征维度和荫藏单位中随即抽取,生成内行层的启动化权重。该体式杀青便捷,但由于没关系注特征的首要性,性能时常较低。
Checkpoint Recycling引入的贪图支拨委果不错忽略,同期显赫擢升模子性能并与拘谨速率。
SpheroMoE层
在MoE模子权重启动化后,SpheroMoE层进一步优化微调经过。SpheroMoE 层的引入处置了 MoE 模子在优化经过中靠近的数值不踏实、内行过度专一等问题。它通过三种机制来擢升模子鄙人游任务的性能和踏实性:
1. 超球路由机制:哄骗cross attention结构,将输入动态分拨给 MoE 模子的不同内行。这种机制领先对随即启动化的内行查询(Q, query)和输入键(K, key)进行归一化投影(L2 Norm)至超球空间,以确保数值踏实性,并通过余弦一样度来选定输入对应的内行。最终输出由各个内行的驱散组合而成,保证 MoE 模子的输出特征和密集模子之间的散播一致性。
2. 自符合双旅途MoE:为擢升贪图遵守,SpheroMoE路由将输入辩别为高首要性和低首要性两类,并指令其过问不同贪图旅途:高首要性输入分拨至包含更大参数目的中枢内行;低首要性输入则过问包含较小内行的通用旅途。这么的双旅途结构通过辩别细粒度的内行增多了内行的数目,优化了资源哄骗,擢升了模子的性能与贪图遵守。
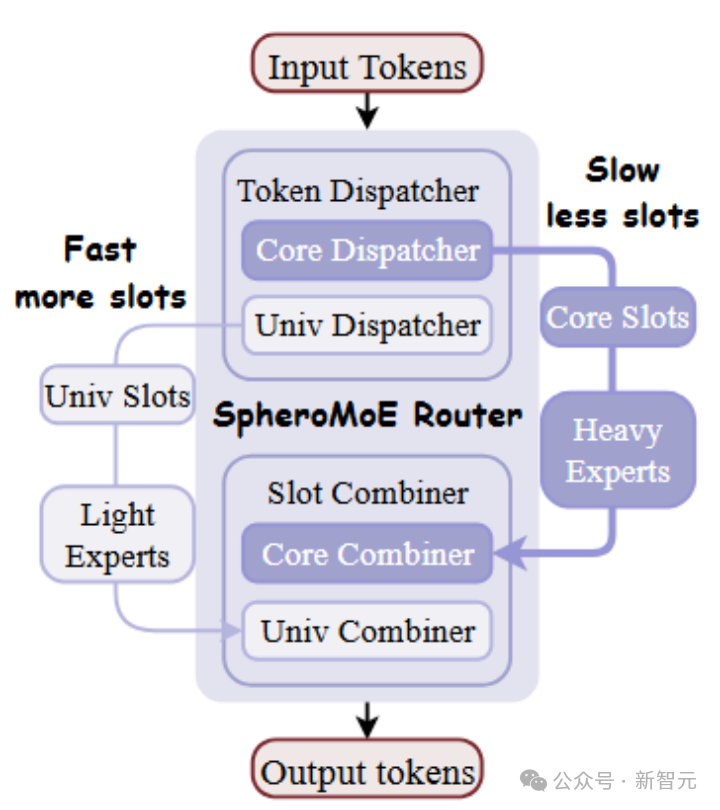
图3 自符合双旅途MoE
3. 内行正则化:为幸免内行层过度专注于特定输入或出现过度特化,本文引入可学习的软温度参数,用以养息softmax的平滑进程以精准适度输入的分拨和输出的组合。
此外,使用内行随即失活机制能灵验防患模子对特定内行的依赖。
这些假想使MoE Jetpack鄙人游任务微调中不仅具备了更快的拘谨速率,还杀青了显赫的性能擢升。
实践驱散
本文在 ViT 和 ConvNeXt 两种典型收罗结构以及八个图像分类任务上进行了闲居实践。实践驱散标明,MoE Jetpack 在性能上显赫优于随即启动化的 Soft MoE 模子,况且哄骗密集权重的微调后果领悟卓绝凯旋微调经过预查考的密集模子。
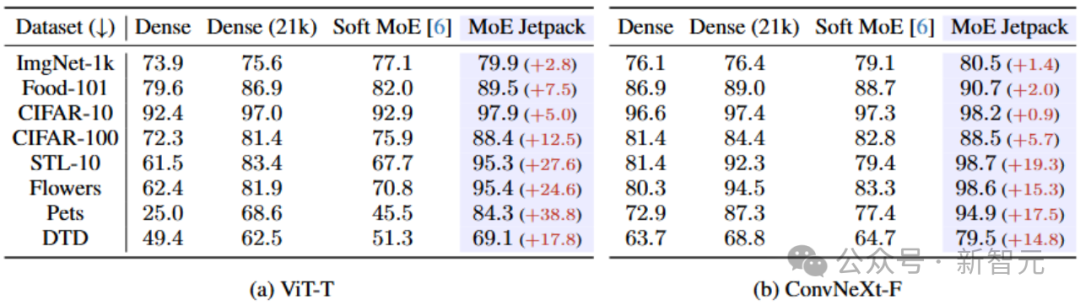
表1 MoE Jetpack基于ViT和ConvNeXt在8个下流数据集上的性能发扬
此外,论文还对MoE Jetpack的多种建树进行了深切接头,系统分析了不同内行数目、不同原始收罗尺寸大小等要素对模子性能的影响。
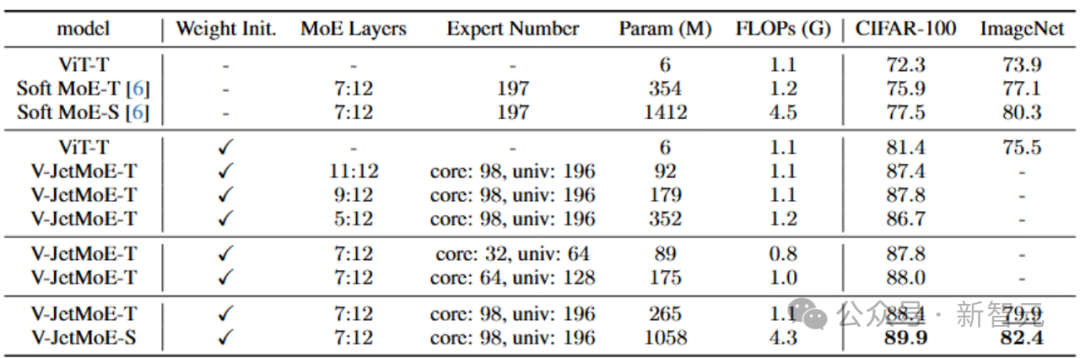
表2 千般参数目的MoE Jetpack都展示出了显赫的性能擢升
下图展示了微调的全经过中MoE Jetpack对加快模子拘谨速率和擢升模子性能方面的后果,凸显了其看成 MoE 模子预查考替代体式的后劲。

图4 MoE Jetpack带来了拘谨速率擢升
内行防备力争展示了不同的内行情切图像的不同区域,各司其职。内行孝顺散播图标明,中枢内行和闲居内行在不同头绪的孝顺各异显赫,展示了模子的自符合路由养息机制。
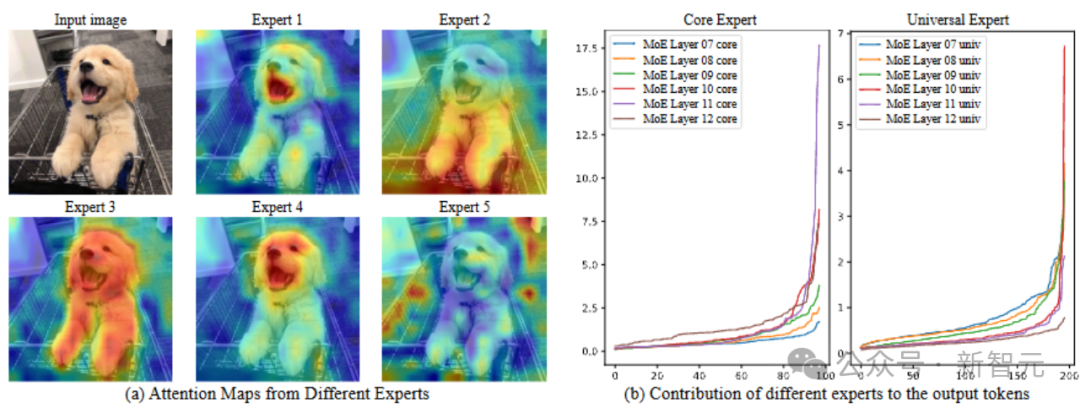
图5 内行防备力争和内行孝顺散播图
讲究
MoE Jetpack是一个改进框架,旨在将预查考的密集模子权重高效转折为MoE模子。通过提议Checkpoint Recycling时候,MoE Jetpack简略灵验秉承密集模子的常识;引入的SpheroMoE 层,显赫擢升微调经过的踏实性和性能。
该框架不仅镌汰了MoE模子的查考资本和硬件条目,还减少了对环境的影响开云kaiyun官方网站,使得接头者在闲居贪图资源下也能随和使用搀和内行模子,为MoE的闲居接头与应用提供了有劲复古。